Political Analysis
Learning outcomes
- When you read a study or news article that says "X causes Y" in politics (lectures cause grades, austerity caused Brexit, social media caused polarisation), you'll know to ask three things before updating your view: how the underlying concept was measured, what would have happened in the absence of X, and how confident the result is once alternative explanations and modelling choices are taken into account.
The toolkit
Political claims tend to be causal. Did austerity cause the Leave vote? Did the minimum wage cost jobs? Did the spread of social media make politics more polarised? You cannot answer these by counting, and intuition is worse than counting. You need a way to compare the world that happened with a world that did not happen, the counterfactual.
Political analysis is the toolkit for that comparison. It overlaps with quantitative social science generally, but the field has its own habits because political data is messy: small samples (only one UK in 2016), non-random selection (countries with constitutions are not a random subset of all possible countries), and outcomes that are themselves contested (what is "polarisation"?).
The toolkit has four parts. Measurement: turning a concept like democracy, polarisation, or repression into a number you can work with. Causal inference: comparing the actual outcome to the counterfactual to identify what one variable does to another. Prediction: forecasting an outcome (an election, a vote share, a protest) from features observable in advance. Uncertainty: reporting how confident you are in any of the above, given that your data is finite and your model is wrong in ways you can name.
Correlation versus cause
A study finds that students who attend more lectures get better grades. Should the university make lectures compulsory? Not necessarily. The same students who attend lectures are also the ones who study harder, ask questions, and do the readings; lectures may contribute nothing of their own and the correlation may be entirely about which kind of student attends.
The cleanest fix is a randomised controlled trial: assign students to attend or not at random and compare. Random assignment guarantees that the lecture group and the no-lecture group are similar on everything else on average, so any post-treatment difference is caused by the lecture. The trouble: in politics, you usually cannot randomise. You cannot randomly assign countries to PR or FPTP, voters to be unemployed or employed, or states to be invaded.
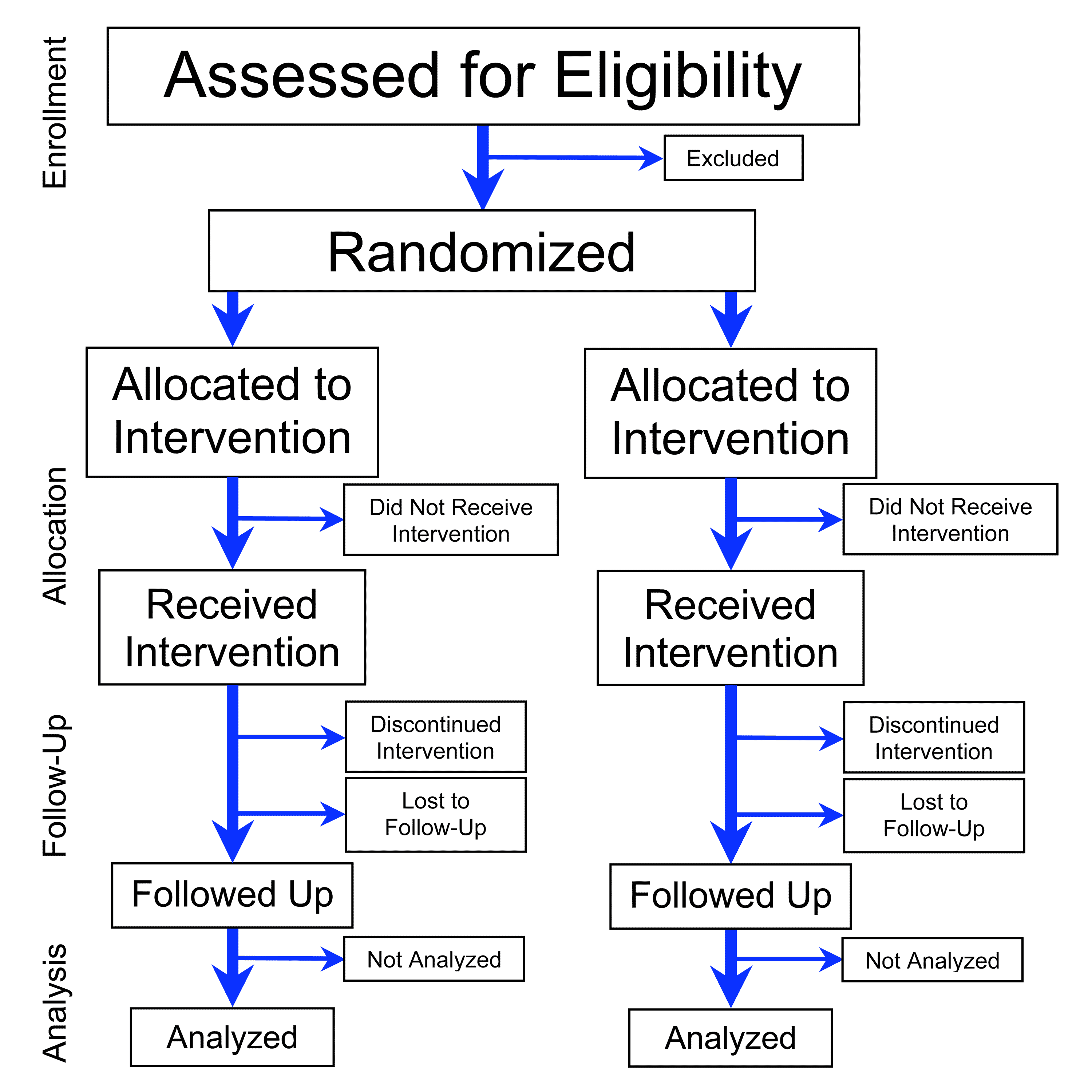
The standard CONSORT flow for a parallel RCT. The diagram makes visible what prose flattens: a single source population is split at random into two parallel arms before treatment, so any later difference between the arms can be attributed to the treatment rather than to who ended up where. Source: PrevMedFellow, Flowchart of Phases of Parallel Randomized Trial, modified from CONSORT 2010, CC-BY-SA 3.0.
Mill set out the logic of comparison without randomisation in 1843: take cases that are similar on everything but the suspected cause, or cases that differ on everything except a shared outcome. Modern designs sharpen this idea by finding settings where something close to random assignment happens by accident. These are natural experiments.
The canonical case is Card and Krueger (1994). New Jersey raised its minimum wage in April 1992. Pennsylvania did not. The two states are similar on most dimensions other than the policy change, so the difference in their post-treatment employment is approximately the causal effect of the wage increase.
The finding reset a debate that economic theory had treated as settled, and made the natural-experiment design the dominant tool in modern empirical social science. Other techniques follow the same logic. Instrumental variables find a third variable that affects the cause but not the outcome except through the cause; the variation in the cause that the instrument induces is treated as if random. Regression discontinuity uses arbitrary thresholds (a school admits students above a test cutoff and rejects those below) to compare cases just on either side. Difference-in-differences compares the change over time in a treated group against the change over time in a control group, differencing out anything that affected both.
Measurement
Numbers in political analysis are usually one or two steps removed from the underlying concept. Democratic quality is not directly observable; what gets coded into a dataset like V-Dem is dozens of indicators (judicial independence, press freedom, vote-buying) that the project's experts judge based on country reports. Each indicator is a fallible proxy. The aggregate score is a model.
Two things follow. First, results often depend on which measure you use. Polity, Freedom House, and V-Dem agree most of the time but disagree on edge cases, and a study that finds an effect with one measure may not find it with another. Serious work checks against more than one. Second, the validity of any quantitative result is bounded by the validity of its measurements.
The same point applies to public opinion, which is filtered through survey questions whose wording shapes the answers. Whether 60% of Americans support "a national health insurance program" or 30% oppose "socialised medicine" depends on the words; both can be true simultaneously.

The V-Dem Electoral Democracy Index for 2023. The map is the output of the model the section describes: dozens of expert-coded indicators are aggregated into a single 0-to-1 score for each country and each year. The continuous gradient is the point. There is no clean line between "democracy" and "not democracy", and a finding that depends on where that line falls is fragile. Source: HudecEmil, V-Dem Electoral Democracy Index 2023, Wikimedia Commons, CC-BY-SA 4.0.
Prediction
Causal questions ask what would happen if you intervened. Predictive questions ask what will happen given what you already see. The two are different jobs, even when they use similar models: a model that predicts the next election well need not tell you what caused the result, and a model that identifies a clean causal effect of one variable need not predict the outcome accurately, because so many other things matter.
The canonical case is election forecasting. Nate Silver's FiveThirtyEight model aggregates state and national polls, weights them by historical accuracy, and adjusts for state-level correlations to produce a probability for each candidate. The 2008 and 2012 US presidential calls were close to the realised outcome. The 2016 model gave Trump a 29% chance on election morning, an unusually high tail probability among forecasters; the lesson the field took from 2016 was not that prediction failed but that correlated state-level errors had been understated, which the next generation of models tried to correct.
Two cautions carry over from causal work. A model that fits the past well can still fail out of sample if the data-generating process shifts (a new turnout pattern, a new media environment). And the headline number (a 71% probability) is not a guarantee; one election in three at those odds is supposed to go the other way.
Uncertainty
Every estimate from finite data has a margin of error. Confidence intervals and standard errors are how that uncertainty is reported. A finding that "the effect is statistically significant at p < 0.05" means that, if there were really no effect in the world, you would see a result this large or larger by chance about one time in twenty.
Two abuses are common. p-hacking is running many statistical tests until one comes out below 0.05 and reporting only that one; the apparent significance is an artefact of the search. Forking-paths analysis is making analytic choices (which controls to include, which subsample to use) after seeing the data and reporting the model that worked. The fix is pre-registration: announce the analysis plan before seeing the outcome data. Modern political-science journals increasingly require it.
Beyond statistical uncertainty there is model uncertainty. Every analysis depends on assumptions (the right controls are included, treatment effects are constant, parallel trends would have held), and these are usually not testable. Honest analysis names the assumptions and shows what happens to the result when they are weakened.
How to read a study
A study claims that austerity caused the Leave vote. To evaluate it, you ask:
- Counterfactual. What would Leave support have been in the absence of austerity? How does the study estimate that? A study that just shows austerity-hit areas voted more for Leave has not yet identified a cause.
- Selection. Are austerity-hit areas similar to non-austerity-hit areas on everything except austerity? If they were also poorer, older, or more long-term unemployed for reasons unrelated to austerity, those reasons may explain the vote.
- Mechanism. What is the proposed channel from austerity to vote? Loss of services, trust in institutions, or a specific policy resentment? The plausibility of the channel partly determines the plausibility of the headline.
- Robustness. Does the result hold under different model specifications, control sets, or alternative measures? Or only under one chosen path?
If any of these has no answer, the claim is weaker than its headline suggests. If all four have answers, you have learned something.
References
- Kosuke Imai, Quantitative Social Science: An Introduction (Princeton, 2018). The standard undergraduate textbook on causal inference and statistical methods for the social sciences. https://press.princeton.edu/books/hardcover/9780691167039/quantitative-social-science
- David M. Diez, Mine Çetinkaya-Rundel, and Christopher D. Barr, OpenIntro Statistics, 4th ed. (2019). Free open-access introductory statistics textbook. https://www.openintro.org/book/os/
- David Card and Alan B. Krueger, "Minimum Wages and Employment: A Case Study of the Fast-Food Industry in New Jersey and Pennsylvania", American Economic Review 84, no. 4 (1994). The natural-experiment study that reset the minimum-wage debate. https://davidcard.berkeley.edu/papers/njmin-aer.pdf
- V-Dem Institute, Varieties of Democracy: Project, Methodology, and Datasets. The flagship dataset on democratic quality across countries and time. https://www.v-dem.net/about/v-dem-project/
- John Stuart Mill, A System of Logic, Ratiocinative and Inductive (1843). The classical statement of comparative method (most-similar, most-different) still in use. https://www.gutenberg.org/ebooks/27942